Running MutationFinder in GATE using the TaggerFramework PR
1. Introduction
MutationFinder is a freely available resource for tagging mutations in biomedical texts. However, it cannot be directly integrated into a text mining pipeline when using the General Architecture for Text Engineering (GATE) framework. Here, I show how to make it available to GATE users using the standard TaggerFramework component, which requires some text wrangling.
2012 Update: Since GATE version 7, a native wrapper for MutationFinder is included with the distribution, so the hack described here is no longer necessary – but it might still give you an idea on how to integrate other, external taggers with GATE.
2. Background
 Mutations, in this context, are modifications in genetic material. A large and increasing number of scientific publications describes the effect of particular mutations, since they can have significant consequences in the medical, agricultural, and industrial domains. If you want to see what a mutation publication looks like, here's an open access paper.
Mutations, in this context, are modifications in genetic material. A large and increasing number of scientific publications describes the effect of particular mutations, since they can have significant consequences in the medical, agricultural, and industrial domains. If you want to see what a mutation publication looks like, here's an open access paper.
However, full-text articles are time-consuming to read. For automated literature navigation, it would be ideal to query the literature, for example, by the impact a certain mutation had on an enzyme. So, one could ask "Show me all mutations that increased the thermostability of the xylanase II enzyme". Using text mining methods, we can attempt to automatically extract these information from the literature and provide them in structured form for querying (like a database or ontology).
For more background information on mutation mining, have a look at our Open Mutation Miner (OMM) project and its publications, in particular this book chapter.
3. MutationFinder
One elementary text mining step is finding these mutations in a text in the first place. This is where MutationFinder, a project managed by J. Gregory Caporaso, comes in: it processes a text and tags occurrences of mutations. For example, if we process the second sentence in the abstract of this article:
"By combining random point mutagenesis, saturation mutagenesis, and DNA shuffling, a thermostable variant, Xylst, was identified which contained three amino acid substitutions: Q7H, N8F, and S179C."
we get the following output from MutationFinder:
S179C:191,196
which means that it detected one of the three mutations, S179C, at text offset 191–196.
4. The GATE TaggerFramework
Since integrating external, stand-alone taggers into GATE is a common use case, it would be nice to have a generic wrapper component that can integrate any available tagger into a GATE pipeline. This idea led to the development of the TaggerFramework PR during the GATE Developer Sprint of Summer 2009 by Mark Greenwood from the GATE team and yours truly. However, this framework makes a number of assumptions on how a tagger works, none of which are compatible with the MutationFinder tagger: instead of outputting all the input tokens with an annotation (a detected mutation), or standard IOB chunks, it only returns a list of the mutations themselves, optionally with their offset in the input document. Hence, we have to map these offsets back to the input document, which requires a bit of work, but is still simpler than writing a GATE wrapper specifically for MutationFinder.
5. Running MutationFinder in GATE
Note: these instructions were tested with MutationFinder-1.1 and GATE 5.2.1/6.0beta running on Linux. It may or may not work with other versions/OSs.
Prerequisites: of course, you must have GATE and MutationFinder installed and running. Refer to their respective documentation for details.
5.1. GATE Pipeline Configuration
Now create a GATE pipeline with the following components:
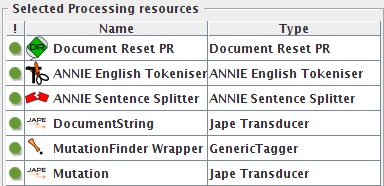
The first three are standard GATE components, the last three are specific for running MutationFinder and discussed below.
5.2. DocumentString JAPE Transducer
The TaggerFramework expects to run input annotations (usually sentences) through an external tagger and collect the output (like POS tags or IOB chunks). MutationFinder expects to run on a complete text, not individual tokens. Hence, we have to copy the document content into a single annotation, which we can then feed into MutationFinder. This is easy with a JAPE transducer using this grammar:
- Phase: Document_String
- Options: control = once
- Rule: Document
- (
- {Sentence}
- ):sent
- -->
- {
- AnnotationSet sSet = bindings.get("sent");
- gate.FeatureMap features1 = Factory.newFeatureMap();
- gate.FeatureMap features2 = Factory.newFeatureMap();
- features1.put("string", content);
- features2.put("string", "mutationfinder");
- outputAS.add( sAnn.getStartNode(), sAnn.getEndNode(), "MutationFinderIn", features1);
- outputAS.add( sAnn.getStartNode(), sAnn.getEndNode(), "MutationFinderOut", features2);
- }
This will store the complete document text in the annotation MutationFinderIn. Since the GenericTagger PR performs a sanity check on the tokens returned by the external tagger by comparing the output with the input string, we have to copy the same string to MutationFinderOut.
5.3. GenericTagger Configuration
Now we can execute MutationFinder on this string and then collect the output, which will be stored as a single GATE annotation. So, you have to create a GenericTagger PR, and set the following run-time parameters:

Note: for the parameter regex, you must make sure there is a single tab between the two
The next tricky bit is the execution of MutationFinder, as it has more constraints on the format of an input document; in particular, it cannot handle any line breaks, as a single document is always expected to be on one line. Thus, a shell script runmutationfinder first removes all line breaks and then executes MutationFinder, making sure to set all command-line parameters correctly. It also reformats the output so that it can be picked up by the GenericTagger PR:
- #!/bin/sh
- #
- # shell script to run the MutationFinder Tagger_Framework PR in GATE
- #
- # set the correct location of your MutationFinder installation dir here
- MF_DIR=/usr/local/MutationFinder
- # prepare MF input file: (fake) document ID, all content on one line
- sed -e "s/[[:space:]]/ /g" $1 > $1.out
- cat ${HOME}/MutationFinder/id.txt $1.out > $1.out2
- sed '{:q;N;s/\n/ /g;t q}' $1.out2 > $1.out3
- # run MutationFinder
- ${MF_DIR}/mutation_finder.py -o /tmp -s $1.out3
- # provide output for GATE
- cut -b 6- $1.out3.mf | sed -e "s/[[:space:]]/ /g" > $1.result
- echo -n "mutationfinder " | cat - $1.result
Note that you have to provide a file with a fake id, id.txt. This file can contain any number (say, 4242). It is needed because MutationFinder expects a number (usually the PubMed ID) appearing before the actual text to be tagged and sulks if there is none.
Also note that MutationFinder does not seem to be able to handle UTF8 input, hence the input text is encoded into ISO8859-1 (without failing on unmappable characters).
5.4. Mutation Transducer
Unfortunately, we're not done yet: as mentioned above, MutationFinder only returns the detected mutation mentions like S179C:191,196, so we cannot use the built-in mapping to Tokens (or any other annotation) that is otherwise automatically done by the TaggerFramework. Instead, we have to parse this output and create Mutation annotations using the offset. This is achieved with the final JAPE grammar:
- Phase: Mutation
- Input: MutationFinderOut
- Options: control = once
- Rule: Mutation
- (
- {MutationFinderOut}
- ):m
- -->
- {
- try{
- // get "MutationFinderOut" annotation
- gate.AnnotationSet mSet = (gate.AnnotationSet)bindings.get("m");
- if(!mSet.isEmpty()){
- try{
- if( st != null){
- for (int i=0; i<myArrMutations.length; i++) {
- try{
- gate.FeatureMap features = Factory.newFeatureMap();
- int colon = myArrMutations[i].indexOf(":");
- int comma = myArrMutations[i].indexOf(",", colon);
- features.put("mutation", mutation);
- features.put("normalized", normalizedMut);
- }
- }
- }
- }
- }
- }
- }
This grammar will create the output "Mutation" annotations, and also stores the normalized name of the mutation (single-letter amino acid format) as a feature:

5.5. Cleanup
In a production pipeline, you might want to remove the temporary annotations. This can be achieved by adding another Document Reset PR with the following run-time configuration:

6. Conclusions
This application certainly pushes the limits of what the TaggerFramework was designed to do, but even with these extensive customizations it was much quicker to deploy MutationFinder in a GATE pipeline than writing custom Java wrapper code.
Of course, none of this would have been necessary if MutationFinder simply behaved like any other biomedical tagger, like the GENIA Tagger, which can be run directly in the GATE TaggerFramework. To see the difference, here's the start of the output of the GENIA tagger on the same text:
By By IN B-PP O combining combine VBG B-VP O random random JJ B-NP O point point NN I-NP O mutagenesis mutagenesis NN I-NP O , , , O O saturation saturation NN B-NP O mutagenesis mutagenesis NN I-NP O , , , O O and and CC O O DNA DNA NN B-NP O shuffling shuffling NN I-NP O ...
As you can see, the GENIA tagger tags every token in the text, and additionally provides chunk information using standard IOB tags, both of which are handled automatically by the TaggerFramework.
With the help of the MutationFinder integration, it is now easy to configure different pipelines containing different mutation taggers, since they can be easily switched in/out of a pipeline with a few clicks in GATE developer; This allows comparing the performance of different taggers, or even running multiple taggers in parallel in a pipeline, which can increase recall (using all the results) or precision (by implementing a voting approach). We can also use all other GATE features, like export to XML, populate a mutation OWL ontology (using the OwlExporter), or provide mutation annotation as a Web service through the Semantic Assistants architecture. Of course, for the application scenario outlined in the introduction, much more natural language processing is required, such as recognizing not only mutations but also proteins, organisms, mutation impacts, and their relations: see our Open Mutation Miner (OMM) system for an implementation of these steps.
6.1. Acknowledgements
Many thanks to Nona Naderi, who contributed to the Mutation JAPE Transducer and extensively tested the MutationFinder GATE integration.
- rene's blog
- Login to post comments

